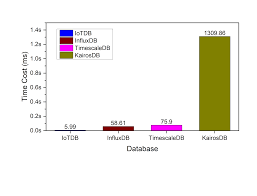
In the era of real-time analytics and high-frequency data collection, speed is everything. Organizations are increasingly relying on time series databases (TSDBs) to handle vast streams of chronological data efficiently. Among these, open source TSDB solutions designed for fast reads are emerging as the backbone of modern data infrastructure. In 2026, businesses that prioritize low-latency queries and high throughput are turning to these databases to extract actionable insights in real time.
The Rise of Open Source TSDB for Fast Reads
Open source TSDB fast reads have become a critical differentiator for businesses handling massive datasets. Unlike traditional relational databases, TSDBs are optimized for time-stamped data, allowing for efficient storage, retrieval, and analysis of trends over time. Open source solutions offer flexibility, transparency, and a vibrant community that continuously improves performance features.
With the growing demand for real-time monitoring, IoT analytics, and financial data tracking, the need for fast reads has never been greater. Queries on large volumes of data must return results instantaneously, and this is where open source TSDBs shine. Their ability to aggregate, compress, and index data for rapid access ensures that users can make timely decisions.
Key Features That Enable Fast Reads
Open source TSDBs designed for fast reads share several core features that distinguish them from traditional databases:
Efficient Time-Based Indexing – By organizing data around timestamps, these databases minimize the overhead of scanning unnecessary records. This structure enables rapid retrieval of specific time ranges without sacrificing performance.
Columnar Storage – Many open source TSDBs store data in columns rather than rows. This layout accelerates read-heavy workloads because queries often require access to specific fields rather than entire records.
Data Compression – High-density compression algorithms reduce storage requirements while maintaining fast read speeds. This balance ensures large-scale time series data can be stored efficiently without slowing down queries.
Aggregation Functions – Built-in functions for calculating averages, sums, counts, and other statistical operations on time series data allow fast computation without moving data to external analytics platforms.
Horizontal Scalability – Open source TSDB fast reads are often distributed systems, enabling them to scale horizontally. Adding more nodes improves both storage capacity and read throughput, which is essential for real-time analytics.
Top Open Source TSDBs for Fast Reads
While multiple open source TSDBs exist, a few stand out for their ability to deliver fast reads at scale. Timecho’s open source TSDB solutions are at the forefront, offering high-performance features tailored for 2026 data workloads.
TimechoDB
TimechoDB has gained significant attention for its ultra-fast read capabilities. Its architecture is optimized for time series data ingestion, and its indexing system enables instantaneous query responses even on massive datasets. With support for high concurrency, TimechoDB is suitable for industries like finance, IoT, and telecommunications, where milliseconds can make a difference.
TimechoLite
For teams with smaller-scale deployments but still demanding speed, TimechoLite provides a lightweight open source TSDB fast reads solution. It emphasizes simplicity without sacrificing performance, making it an ideal choice for startups and research projects that need rapid prototyping and testing.
TimechoCluster
TimechoCluster is designed for distributed environments. Its horizontal scalability ensures that even when the dataset grows to billions of points, read performance remains consistently high. Its intelligent sharding and replication strategies reduce read latency while providing fault tolerance.
Best Practices for Achieving Fast Reads
Implementing an open source TSDB fast reads solution is only part of the equation. To maximize performance, organizations should follow best practices:
Optimal Data Retention Policies – Store only the necessary data at full resolution and downsample older records to reduce query times.
Pre-Aggregation of Metrics – Compute commonly used aggregations during ingestion to avoid repeated heavy queries.
Efficient Query Design – Structure queries to leverage time-based indexes and avoid unnecessary full-table scans.
Monitor and Tune Performance – Continuously track database metrics such as read latency, cache hits, and disk I/O to proactively identify bottlenecks.
Leverage Built-in Tools – Use the monitoring and visualization tools provided by Timecho TSDBs to optimize query performance and quickly pinpoint inefficiencies.
Use Cases Driving Adoption
Open source TSDB fast reads are particularly valuable in scenarios where speed is critical:
IoT and Sensor Data Analytics – Devices generate continuous streams of data, requiring databases that can ingest and query high-frequency readings in real time.
Financial Market Analysis – Traders and analysts need rapid access to historical and current market data to make informed decisions within milliseconds.
Application Performance Monitoring – Observing application metrics, server logs, and user interactions requires fast queries to detect anomalies and resolve issues promptly.
Energy and Utilities Management – Time series data from smart meters and grid sensors allows real-time monitoring of energy consumption and predictive maintenance scheduling.
Why Open Source is a Strategic Advantage
Choosing open source TSDBs for fast reads provides both technical and business advantages. Transparency ensures that developers can understand and optimize the database internals. The active community contributes improvements, bug fixes, and extensions, enhancing performance continuously. Moreover, open source solutions like Timecho reduce vendor lock-in and provide the flexibility to adapt to evolving requirements.
Future Outlook
In 2026, the focus on real-time insights and the explosion of time series data will continue to push the limits of TSDB performance. Open source TSDB fast reads will remain a cornerstone of this trend, with innovations in indexing, compression, and distributed architectures driving the next generation of high-speed data analytics. Organizations that invest in these solutions today will be well-positioned to leverage the power of instant, data-driven decisions.
Conclusion
Fast reads are no longer a luxury; they are a necessity for businesses operating in data-intensive environments. Open source TSDBs like TimechoDB, TimechoLite, and TimechoCluster provide the tools and infrastructure to access, analyze, and act on time series data in real time. By adopting best practices and leveraging the unique features of these databases, organizations can unlock unparalleled speed and efficiency, ensuring that they stay ahead in a competitive landscape.
Timecho’s commitment to innovation in open source TSDB fast reads ensures that businesses in 2026 can handle even the most demanding time series workloads with confidence and precision.